
Chapter 6: Complexity
"It always seems impossible until it's done." - Nelson Mandela

Maybe I’ll see you at the Space Economy Summit on Oct 11?
Planning to succeed
Systems engineering is the science and art of dividing a project into manageable pieces so that when all the pieces are finished and put together, the project does what you want it to.
Agenda
The next big thing
How to pull a rabbit out of a hat
Something neat I found on the internet
Dispatches from the soccer pitch
Cautionary tale
Making the Impossible
My science career started in the physics department machine shop at the University of Washington, where my first job was cutting and doing quality control for metal tubes. Lots and lots of metal tubes, because the ATLAS particle detector at CERN, which would later discover the Higgs boson, needs a way to measure the flight of very fast-moving charged subatomic particles. These tubes, filled with argon, have a tensioned wire down the middle, and a high voltage between the wire and the tube. When, say, a muon zips through the argon at nearly the speed of light, the gas may be ionized, which makes the wire go zap!, which lets us measure where and when the muon was. Going from zap! to knowing something useful depends on accurately knowing where that wire was, down to the micron.
Our project, for which I was the guy cutting metal, was to figure out how to know where the tubes and the center wires were. Ambitious discoveries depend on visionaries, and also on some kid in the basement obsessing over a feeler gauge on a granite slab. We ultimately found a hundred or so ways not to do it, our small contribution to the enormous effort that made ATLAS.

In graduate school, I researched a very specific noise source for LIGO, the gravitational wave observatory, which tells us that not only is the universe is full of neutron stars and black holes, but that much of the matter made of elements heavier than iron comes from these neutron star collisions. Part of Kip Thorne’s genius was to write a textbook, called Applications of Classical Physics, which derived all the physics that would go into building LIGO, or anything else, for that matter, and make all the physics grad students at Caltech take the class.
At JPL, I made a lot of things become possible — like the Deep Space Atomic Clock and the Cold Atom Lab. In the previous chapter, we described how methane gas leaks are much, much worse than we thought, and also how they can be affordably measured and mitigated, from space.
All these projects were impossible, until they were done. The first part is recognizing that a solution may exist. The next part is developing the theoretical basis for how to do it. But then how do you get from a that theory to an actual, physical machine that works? That’s systems engineering, which is what I’ve been learning how to do for the last 20 years.
Cat Herding 101
Systems engineering is not for building parking garages or bridges. For those, you should know what you’re doing. Rather, systems engineering is for building the previously impossible. And I think we now know enough about it that we can describe a system for doing it. Broadly speaking, I’ll divide systems engineering into three areas of practice: architecture, validation, and verification.
The architecture function is to develop and manage the requirements, interfaces, statements of work, design memos, schedules, risks, and operation scenarios. The purpose of this work is to provide the teams and vendors building each of the components with enough information to do their jobs, and to mediate the exchange of information among those teams to prevent delivery delays caused by “known unknowns.”
Interesting projects usually start with a half-baked theory, often with a shopping list of parts to buy. Akin’s Law #38: Capabilities drive requirements, regardless of what the systems engineering textbooks say. Design is also iterative, so we explore options in a “study phase,” where we develop a handful of alternate architectures, and assess the maturity and capabilities of each.
I’m tracking a dozen or so teams developing things to launch with a SpaceX Starship, so let’s use a 20,000 kg, 10,000 W spacecraft as an example.
Architecture
Each component we choose interacts with every other, so the purpose of this architecture study is to find at least one plausible implementation plan that is affordable, reliable, and robust to supply variations.
For the propulsion system, one could purchase a number of pre-built, standard space tugs, with their own solar panels, batteries, computers, attitude control, and engines, and use them as individual thrusters. Or, once could design a custom control, power, propulsion, and navigation system. Which is faster and cheaper? It’s not always obvious, as there are economies of scale when you can mass-produce components. For example, ViaSat-3 has single, large mesh antenna reflector, while AST SpaceMobile has a large phased array made out scores of identical panels. While neither of these satellites are commercially operational, they do demonstrate the extremes of the design options.
For attitude control, how does it change direction? Do you use the thrusters, or are there reaction wheels? How long does it take to turn a thruster on? What’s the risk of a valve getting stuck open? One big reaction wheel (K2 Space is working on this), or several little ones that have been previously proven?
For power, do you use silicon solar panels that may lose half their efficiency from 5-10 years of radiation damage, or GaAs panels that are not currently produced in the needed quantity?
In every interface, there is a tradeoff between duplication of effort and complexity of the interface itself, and there is always hidden complexity, so the architect does trade studies, thorough enough to understand and document these decisions. Each choice can be described as a set of mathematical equations, relating engineering parameters to a key performance metric. Once you know the form of the equation, it becomes fairly straightforward to write the requirements for all the subsystems.
Architecture, then, becomes deriving and tracking the interrelated equations that describe the physics of the machine you’re building.
Validation
Validation is ensuring that the design, as expressed through the requirements, interfaces, and other artifacts, will give you what you actually want. Or, if it doesn’t, you know how it doesn’t. We use the physics equations to write mathematical simulations and error budgets, relating the physics of the observatory operation to the specifications and tolerances described in the requirements flowdown. Of course, all models are wrong, but some models are useful. These simulations need sufficient fidelity to answer questions like, “how much thermal conduction is needed between the avionics vault and the radiators?” and “What’s the temperature range over which the heat pipe will work?”
For shared resources, like power, compute, and navigation, budgets are developed to keep track of the interactions among the various spacecraft systems. Where the spacecraft points, relative to the sun, determines power generation, and temperature gradients. How the spacecraft moves, to change where it points, may affect power consumption, internal vibrations, or mission utility of, say, a telescope that wants to look at a particular asteroid.
For the Deep Space Atomic Clock, I wrote a time-domain control system simulation to compute how the clock would be affected by disturbances, like magnetic fields exported from the torque rods, the changing direction of the Earth’s magnetic fields, and temperature drifts of the electronics as the spacecraft moves from the day to night sides. If you’re planning to visit the asteroid belt, having the clock frequency changing by a part in a trillion could lead you to turn on the thrusters at the wrong time, and miss Ceres altogether. One of the components, the master oscillator, was out of spec, and the project had to decide whether to take the cost and time hit to order a new one. The control system simulation showed that we could take it as is, by tightening up tolerances elsewhere, instead of paying for the 3-month delay to build a new one.
Good validation means that you know how to change the requirements to adapt to the unexpected. Knowing which requirements are better described as “goals” saves time and money.
Verification
As the project (including space and ground segments) is built, following a validated architecture, verification assures that the final product is what the customer asked for. A verification program, alongside the other engineering work, provides the pedigree, an assurance that every delivered component and system do what they’re supposed to. In the study phase, the we decide on a test & analysis matrix, to broadly define what gets tested, at what level of integration, and how. For previous “too big to test” programs, we invested early in identifying the component measurements that would enable the design of a “digital twin,” with sufficient fidelity to confidently reject the hypothesis that the final product would not meet the mission objectives. Mind you, a digital twin that hasn’t been verified against the actual product is just a simulation.
Planning a verification program also reveals what test equipment will be needed – expenses which are often overlooked even by national space agencies.
At each level of assembly, some kind of test, analysis, or demonstration is performed to gather data about the delivered articles. The systems engineering team uses the verification program to identify excursions from intended results, and then propagates those variations through the error budgets and models to assess impacts. In many cases, accepting products “as-is” saves a lot of time, provided we can adapt. When the final product is delivered, the rollup shows that the process was followed. Verification also includes documenting standards for design and workmanship: were torque wrenches calibrated, fasteners inspected for voids, and glue mixed correctly? It’s becoming more cost-effective for the systems engineer to take responsibility for setting up a system to collect and monitor all these records, than to make every engineer and technician responsible for reporting their own progress.
Building it
If you think of the V and V Process as overlaying the requirement flowdown, then it establishes the order of operations for integrating and testing our spacecraft.
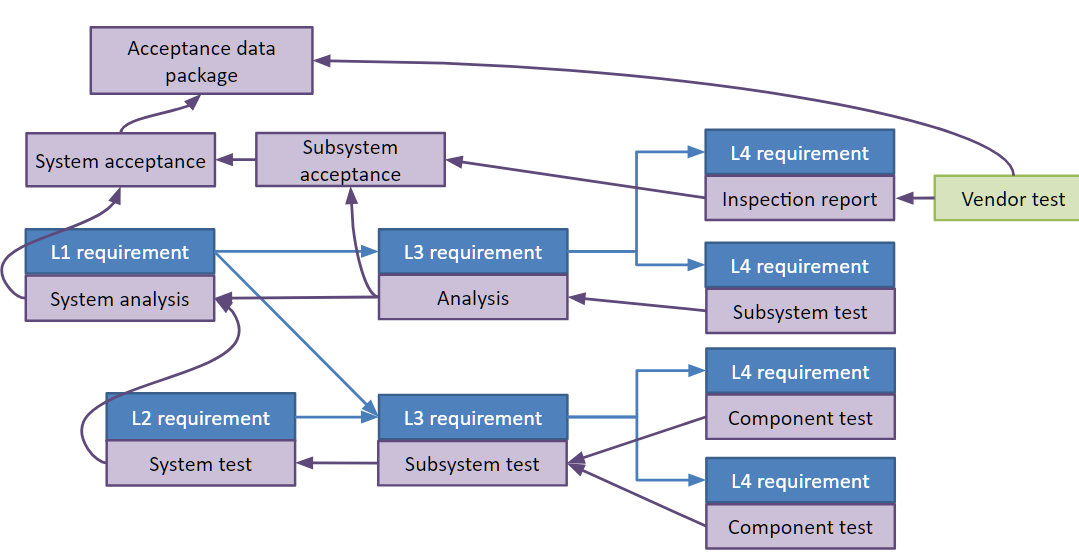
The difference is that while systems engineering is heavy on databases and physics, integration and test tends to be about scheduling, cash flow management, and human factors. As the spacecraft comes together is not the time to “figure it out as you go,” so during the study phase, you draw a storyboard to describe the assembly, integration, and test. The tests will be described, with their own statements of work and test requirements. The analyses that connect tests to the verification rollup will have a problem statement, and a computation approach identified so that their software can be prepared during the implementation phase.
Systems engineering is also about managing risk. Flight is unforgiving of any oversight or inattention, so while Keep It Simple and Successful is our motto, we recognize that any high-performance system is inherently complex. Jean Carlson’s and John Doyle’s Highly Optimized Tolerance theory helps explain how “robust, yet fragile” comes about, and why complex systems fail in complex ways.
Over the years, the strategy that I keep coming back to is best described as, “put all your eggs in one basket, and then watch that basket very closely.” Doyle refers to the “Waist of the hourglass,” a pattern that appears over and over again in nature and technology, to achieve robustness through complexity. Go ahead, follow the rabbit. The basket, when it comes to engineering management, is the process to communicate concerns and risks, across the project, and among and between performing teams.
What’s next
Traditionally, engineering, systems engineering, quality, integration and test, design-for-manufacturing, and manufacturing took place not only in different teams, but in different buildings.
Today, we have better computers, so the moneyball play is to tear down those silos. Integrated product teams are becoming the norm, which means, as complex systems fail in complex ways, there’s still a need to enforce rigor. Teams can benefit by starting new projects with a mature systems engineering process. Early decisions to establish the structure and systems capable of coordinating the performing teams can set a company up to succeed or fail.
The old way was to have a systems engineering team, and then each functional group would hire a person to deal with the systems engineers. We can do better now, and projects can choose to have a small systems engineering staff who support the implementing teams, and software can avoid the need for tasking people to continually provide inputs to project management.
What about manufacturing itself? Manufacturing today runs open-loop: you get what you get, and you either accept or reject it. The process of making stuff can also a feedback control process. For instance, if you’re laying down carbon fiber, are you measuring the tension as you do it? Is that more or less than you were expecting? What changes can you make in the next layer to compensate for deviations in this layer?
Manufacturing and quality assurance go along with systems engineering. Quality is not added as an afterthought, and neither is the decision of how many widgets you want to make. As we start to adopt topological optimization and generative design, can we also integrate feedback control into the build process (“GPT, given this build history, how much should I tension this adjustment rod”)? Small production lines are an elusive goal — you can make 1 spaceship, or 1,000 spaceships, but it’s a struggle to make 10 and still make a profit.
Cynefin
It’s a Welsh word. Don’t ask me how to pronounce it.
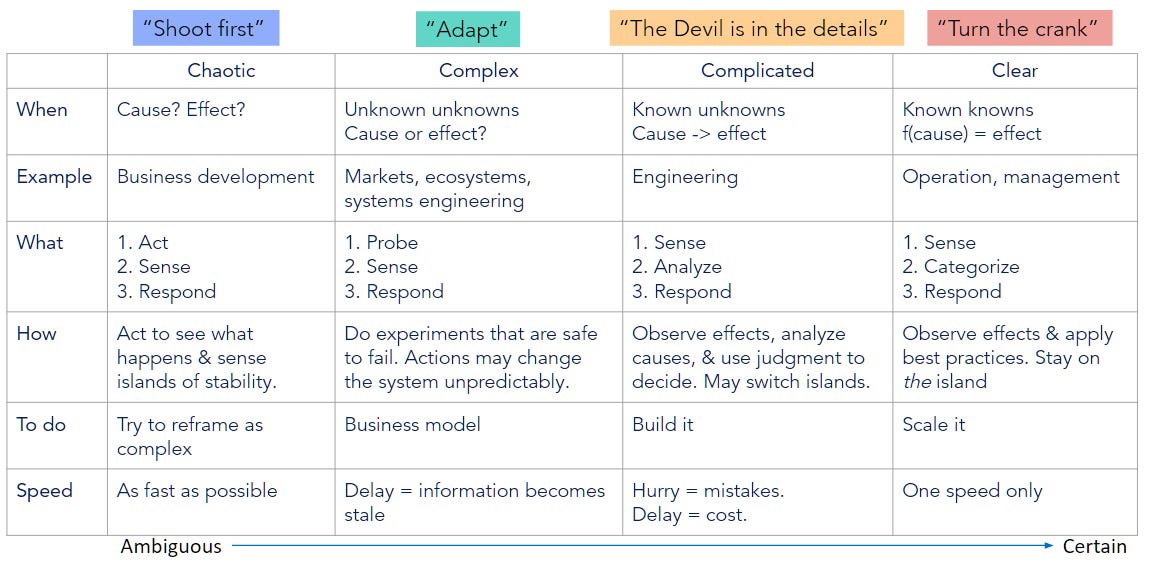
You’ve probably heard of Technology Readiness Level, maybe Application Readiness Level, and perhaps lament the TRL Valley of Death. Well, wherever you are on those game boards, Dave Snowden’s Cynefin framework tells you the appropriate methods to use.
A project, a startup company, or a toddler’s birthday party starts in disorder. Defying entropy, we travel through the lands of Chaotic, Complex, Complicated, and finally arrive Clear. As we travel from one domain to another, the customs and habits that win friends in one of these lands may get us thrown out of the tavern in another.
Here’s the infographic, where each of those wavy lines represents a Valley of Death

An Architect usually starts work in the Land of Chaos, where the customer doesn’t really know what she wants. So we try a bunch of different ideas (or trade studies) to see what sticks. The point is to search of islands of stability — configurations where there seems to be a local optimum, or at least a saddle. There may be more than one, and the purpose is to find that they exist, at all, which would justify the effort to move to the next land. Venture capital can be suitable if you think you’ve found 8 - 12 stable islands.
In the Complex domain, we have an island, but we don’t know how big it is or how steep it is. An Integrated Product Team works great, because you can shout “here be Dragons!” from one end of the island, and everyone can hear you. The optimal practice here is to conduct a series of experiments to map out the island. By “map,” I mean the governing equations, with starting points for the variables, and values and uncertainties for the parameters. If you have that under control, you’re ready to go to market.
Complicated is like complex, only you don’t try to leave the island, and it’s best to have a management structure, so that the explorers, who used to talk to each other all the time, get to focus on their individual tasks without having to be bothered all the time with stories from the other side of the island. People know what they have to do to stay on the island, and monitor the information flow for indications of unknown unknowns. This is where growth capital comes in
Clear is when everything is running smoothly, so you mostly don’t need to think. Most of what can go wrong, has done so before, and there’s a quick reference card that says what to do about it. You don’t need an engineering team anymore, so you sell out, buy a boat, and go looking for new islands.
Here’s the cheat sheet:
Tales from the soccer league
Growing up in Seattle, I played soccer. While nobody would have accused me of notable greatness, I took it seriously, was regarded as a competent sweeper, and played on a travel team through middle school. What led me to give it up was being bullied by the other boys on my team.
So, one of my priorities in volunteering to run my kids’ city league is to make everyone feel like they’re wanted and appreciated. We know that Pasadena has a substantial fraction of families with low incomes. Are they being included? By geocoding and mapping the home addresses, it was obvious that the kids living west of Lake Ave were underrepresented. What do to about that?
Act, sense, respond
Maybe they weren’t invited? Go to PTA meetings.
Maybe it’s culturally unexpected? Include flyers with kindergarten registration forms.
Maybe they feel excluded? We should have a diversity policy. Use photos that shows diversity among kids and parents.
Maybe they can’t afford it? Offer a pay-what-you-can policy.
Maybe they’re bullied or stigmatized? Implement a formal reporting and surveillance program to monitor behavior.
Maybe they’d rather play other sports? You know what, that’s totally fine. We bought the softball league a new scoreboard and ride-on mower.
Maybe AYSO is perceived as inferior? Improve coach education, compete in tournaments, win, and take credit for running a world-class youth athlete development program.
Maybe they’re afraid they aren’t good enough? Offer development programs for different skill levels, with varying levels of family commitment.
Maybe they can’t afford it? Have a used shoe exchange. Normalize wearing hand-me-downs. Buy new equipment for families who are really struggling.
Maybe they can’t get there? Make schedule accommodations for families with access issues. Takes a lot of computation.
Removing the financial obstacle, with pay-what-you-can, no questions asked, turned out to be a network effect. In the first year, the league awarded $3k of scholarships, which was about normal for covering the costs for about 25 kids, or 2% of the overall population. Then they told their friends, and the next year there were $6k of scholarships, and parents donated an extra $3k to offset it (it’s truly pay-what-you-can: you can pay less, or more, than the suggested amount). So it looked like a wash.
Probe, sense, respond
Then there was a pandemic. Kind of a bummer. Coming out of the pandemic, we decided to promote the league to underrepresented schools. Talking with the PTA at a school with a high portion of kids with free/reduced lunch, it was clear that “cost is no object” was what gave them permission to encourage the school’s families to join. Knowing that none of the 1st graders would be left out made it easier for all the others to feel comfortable trying it, as a group.
For the 2022 season, 200 kids received financial assistance, and for 2023, 293 kids, almost 12% of the total population. While that sounds expensive, we have enough history to estimate the fraction of people requesting assistance, the fraction who will contribute more, and build it into the budget, and the population of kids playing grew by much more than the number of discounts awarded. A few donors (thank you, Capital Group and LA84 Foundation) felt
Sense, analyze, respond
Do people take advantage? Yes. Two of them. We know who they are.
Do they really pay what they can? Yes! Some people will give themselves a $40 discount, because that’s what they feel they can afford at the time. If we offer a choice between paying $50 or $100, about 1/3 will pay the $100. It’s all in how you frame it. Amazon will pay me if you buy Influence: the Psychology of Persuasion.
Do the parents from the new school volunteer? Not in the first year. In the second year, they volunteer to coach or referee at an above-average rate. This suggests that we can target one new school per year to increase enrollment.
Oh, about that exclusion bit? AYSO’s national organization has made a deliberate effort to show more representation. Remember the 1990’s, when movie posters always featured a white person in the middle, and people of color backing them up? Well, here’s what centering people of color looks like:

Some people we’ve showed this to asked, “where are all the white people?” Count them. They’re there, just not the center of attention.
The Next Big Thing
I met Steve & Zeke, founders of Prewitt Ridge, through Creative Destruction Lab’s Space Stream, and invested in their seed round, after over a year of begging them to take my money.

What are you trying to do? Verve makes it easy to capture requirements when team explores the design space, rewarding to connect requirements to error budgets and simulations, and fun to see what happens when changes ripple through all the other models and budgets.
How is it done today, and what are the limits of current practice? It’s a full-time job to capture requirements in an ancient and kludgey database, which generates a document. Usually, someone’s job is to babysit a specific document, and talk to all the other document owners to monitor the knock-on effects of changes.
What's new in your approach and why do you think it will be successful? People use a variety of tools to manage budgets and simulations. Verve works with those (Excel, Google Sheets, MATLAB, Jupyter, …) to adapt to the way engineers want to work and keep track of how the disparate parts of a project are connected to each other. It rewards you for keeping models and estimates up-to-date,
What difference will it make? Teams that use Verve will outperform teams that use the established requirement capture software. Verve also enables higher levels of integration across functional disciplines, so you can analyze and understand complexity that was infeasible before. Design engineers can directly understand the relationships, without having to go through a separate layer of managers.
What are the risks and the payoffs? Verve is a new way of working that appeals to digital natives. Teams that are comfortable with the traditional project lifecycle may be reluctant to adapt. But teams that use Verve can outperform those that don’t, with fewer people.
Lesson learned
Our refrigerator died last month. Fortunately, we have a redundant backup freezer in the basement for fish from Lummi Island Wild, so we didn’t lose too much.
You may have noticed that household appliances nowadays are a) expensive and b) crap. Well, my recommendation is to plan for failure, and have a backup freezer. We were fortunate to be able to replace just the compressor, but next time, the good ol’ ozone-depleting refrigerants may not be available. Request for startup: energy-efficient household refrigeration with an inert working fluid. It could even be fairly expensive, because the competition is unreliable.
Oh, and on the fish subject: twice a year, we organize a bulk shipment of sustainably harvested seafood that Sierra and Ian catch and source from the Pacific Northwest. Drop me a line if you’d like in on the buying club for October.
If you liked this and want to catch up, check out previous episodes:
Chapter 0: Recap
Chapter 1: Rethink Everything
Chapter 2: Power Laws and Disruption
Chapter 3: Incentives
Chapter 4: Failure
Chapter 5: Strategy
Subscribe to get more like this. More about me at shantirao.com.
If you’ve made it this far, here’s my request of you: change the world. Do something meaningful to help people, because you can.